A simpler cross-chain bridge architecture
A simpler cross-chain bridge architecture
Cross-chain bridges are hard and complex. What if it wasn’t like that?

Serverless tends to push the 'edge' paradigm. The app server lives close to the user to save latency. But it's problematic if you have a database because, generally, you will have multiple db queries for each page / API request. Let's talk about that
I think an important topic when thinking of what architecture you should use for your web app, be it web2 or web3, is latency.
Latency is really important. It is the time it takes for data to get from point A (a server for example) to point B (another server, or a client/user). The further away the two points are, the more time it will take for data to travel.
You can use this tool https://benjdd.com/aws/ to visualize the latencies between different AWS data centers.
One way in which the web development industry has tried to fix latency is “on the edge” deployments. The idea is that if you can take the server closer to the user, they’ll get the server rendered page or the API response faster.
And it makes sense, until you consider how the page / API response is generated. It usually needs data from a data store (database, cache, etc).
Generally speaking, most web apps have only one central data store because it’s hard to geographically distribute data (this is why distributed systems engineers are valued highly).
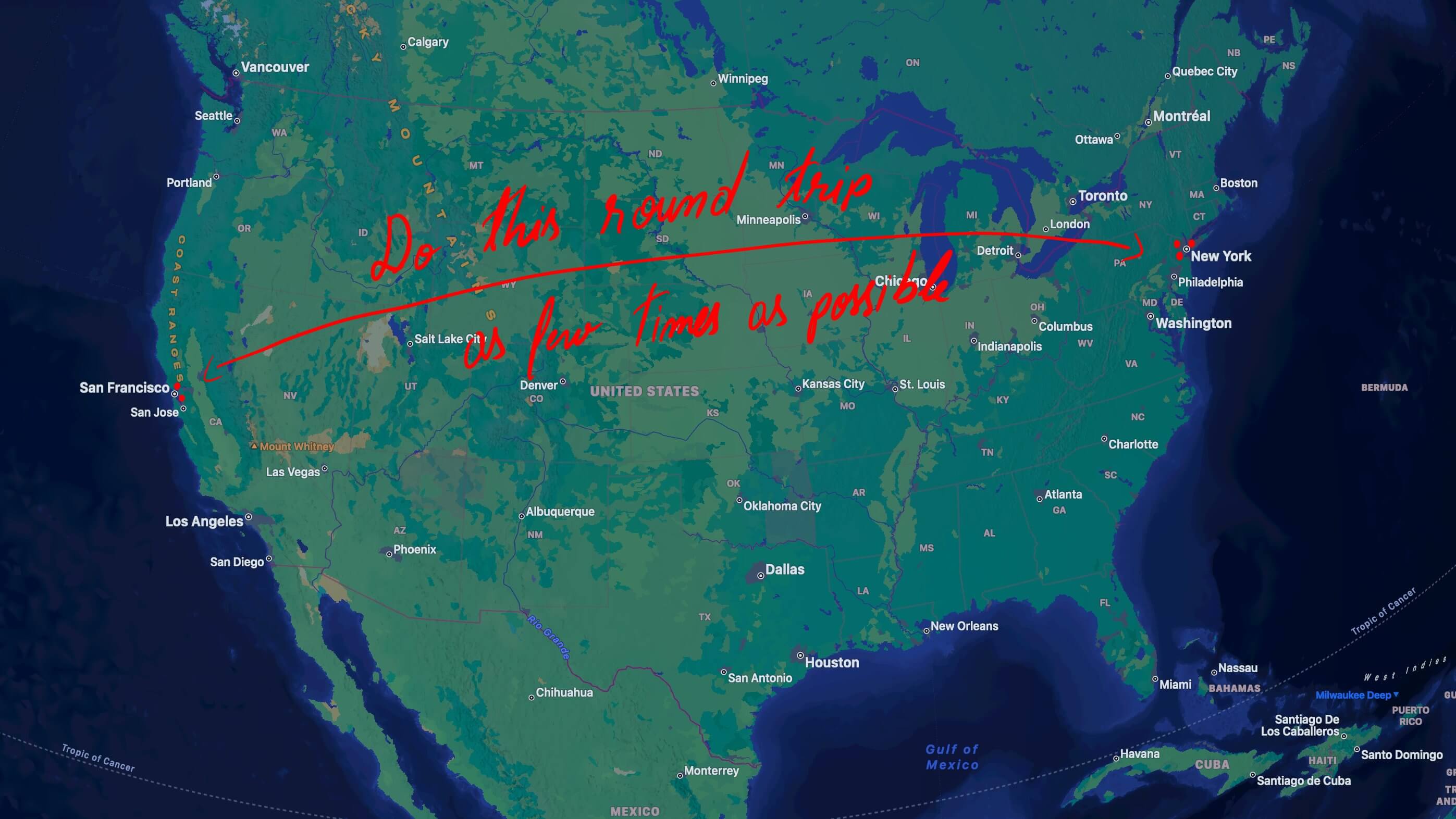
So in a “user <-> app server <-> database” situation, if you moved the app server closer to the user by taking advantage of something like Vercel Edge Network, you did save “user <-> app server” latency. But you’ve added to the “app server <-> database” latency. And that tends to be an overall net increase in latency per page / API response.
Why so? Because we generally need to do more than one query per page / response, in most web applications.
So now instead of incurring the long latency once, you do it for each and every database query. And your web app becomes slow.
You can fix this, as I alluded to above, by having a distributed data store.
And while it’s easier to do now than 10 years ago, especially for read operations, it’s still extra dev ops & architectural overhead… For a problem that could have not existent in the first place.
Note, my point here is that you should keep your compute layer close to the data layer and only incur the latency once when delivering the data to the user.
Now, to exemplify how problematic this can actually become, I’ve made a small app (deployed on DO in NYC1) that does latency tests to:
I’ve added a picture below with the results from yesterday. The live app is not deployed anymore, but the code is there if you want to deploy it yourself.
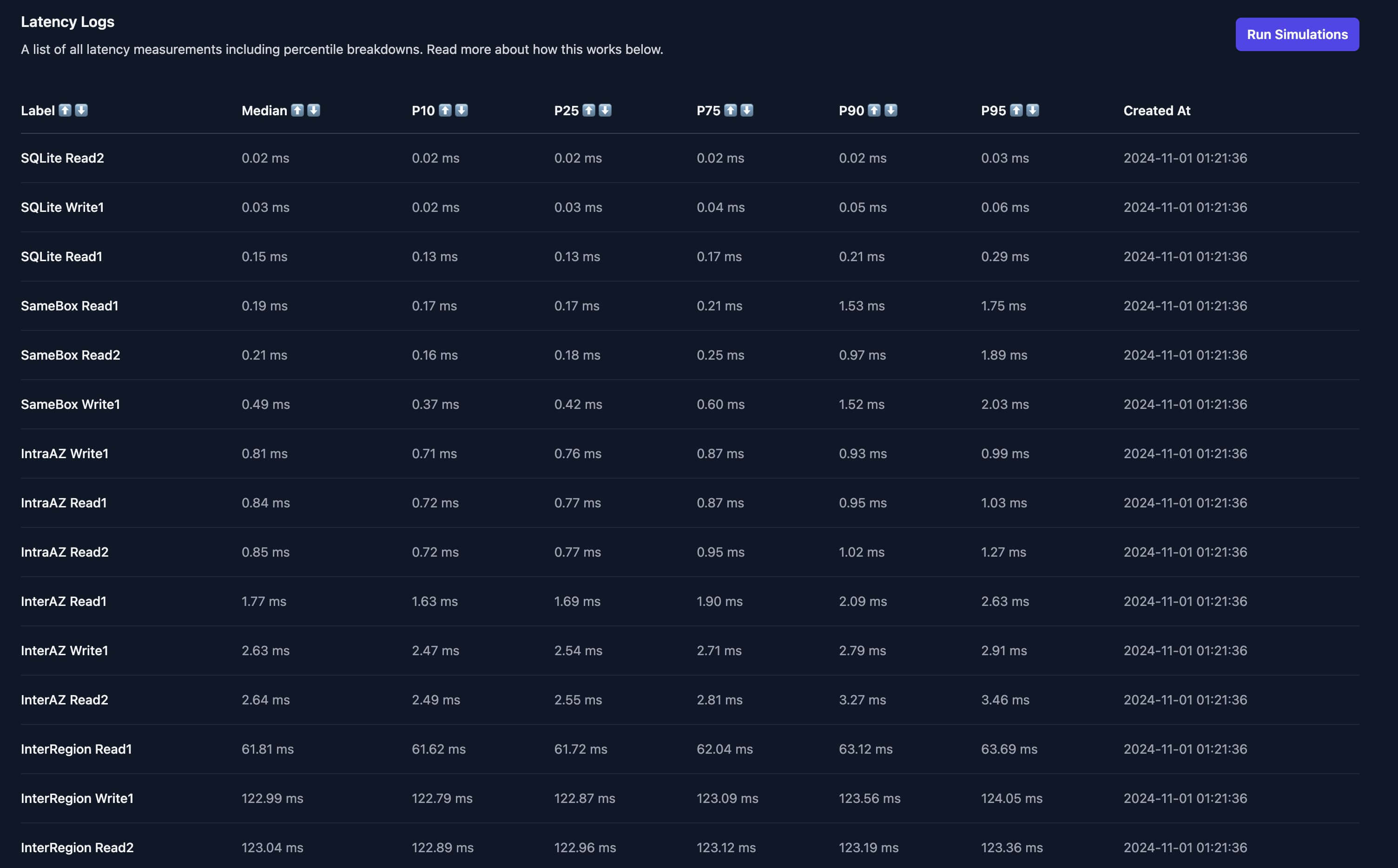
You can quickly make a few observations. Intra-AZ (same datacenter) is really not bad, you could do 10 queries and it not affect the response time in a major way
But inter-region is awful (60-120ms) and it will be slow your app down a lot. Just 3 queries, and you’re ~270ms slower.
270ms is enough for your user to feel it, especially when you account for the fact that this is latency only, not any time spent doing heavy queries or compute.
Anyway, thanks for reading. I also have a video on this on my channel if you prefer that.
Cross-chain bridges are hard and complex. What if it wasn’t like that?
An in-depth comparison of SQLite and PostgreSQL for web development, highlighting their strengths and use cases.
Different networks work differently, but Ethereum is the core inspiration for EVM-based networks. Knowing how these work is useful if you want to work in crypto.